Model Selection in Machine Learning
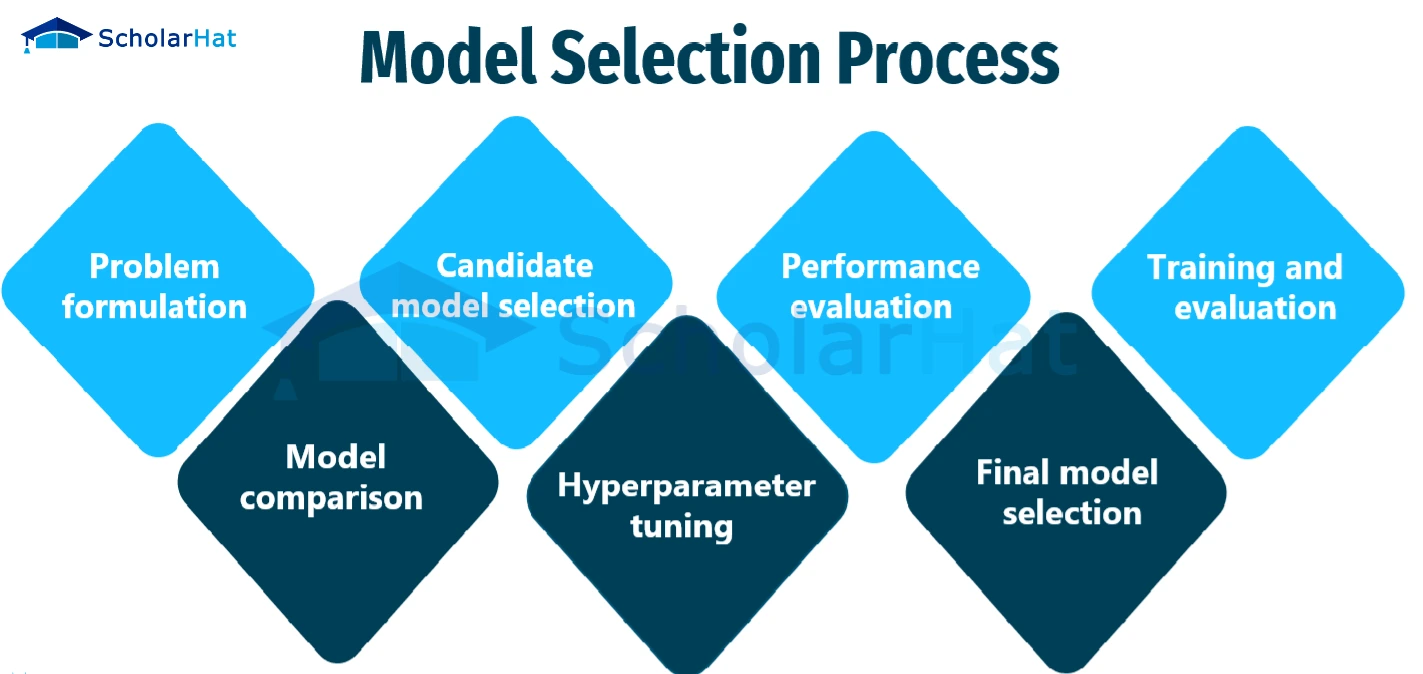
Model selection is a crucial step in machine learning where you choose the most suitable algorithm and its hyperparameters for a specific task and dataset. It involves evaluating and comparing different models to find the one that generalizes well to unseen data, avoiding overfitting or underfitting.
- AIC (Akaike Information Criterion) from frequentist probability
- BIC(Bayesian Information Criterion) from bayesian probabaility
These are calculated using Log-likelihood which includes MSE (regression) and log_loss such as cross_entropy (classification).
Load Libraries and data
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Load or prepare your data (replace with your data loading)
data = pd.read_csv("your_data.csv")
X = data.drop("target", axis=1) # Features
y = data["target"] # Target variable
Train Test Split or CV
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Define and Train Models
# Define models to compare (using default hyperparameters for simplicity)
models = {
"Logistic Regression": LogisticRegression(),
"SVM": SVC(),
"Random Forest": RandomForestClassifier()
}
output = {}
# Train and evaluate each model
for name, model in models.items():
model.fit(X_train, y_train)
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
print(f"{name} Test Accuracy: {accuracy:.2f}")
output[name] = accuracy
Pick the best performing model
print(output)
Once the best model is identified, finetuning can be performed on it to further improve the performance
Interactive Graph